Sentiment Analysis of r/Formula1 Comments: Examining Community Responses to the 2019 Formula 1 Season
Nat Rubin
Introduction
The r/formula1 subreddit is the internet’s largest and most active community for fans of Formula 1, the world’s premier motorsport. Each race weekend, the moderators of the subreddit post a Post-Race Discussion thread, where fans can discuss the race with each other. These threads provide an exciting opportunity to determine how this fan community feel about individual races. Using sentiment analysis, I want to determine which 2019 Formula 1 races attracted the most positive and most negative comments. To do this, I used the sentimentr package. The advantage of using sentimentr over other sentiment analysis packages is that it combines sentiment dictionaries with more sophisticated understandings of negations (such as not good) and amplifications (such as very good). The package can process sentences, allowing for nuance that may be lost in processing words one at a time.
To begin, I loaded my packages. I used tidytext to unnest tokens, utf8 to convert the comments into a useable text format, and ergastR to load F1 statistics.
library(tidyverse)
library(sentimentr)
library(tidytext)
library(ergastR)
library(utf8)
library(leaflet)
library(ggrepel)
library(prettydoc)Sentiment Analysis
First I import the comments I scraped from Reddit. I used the RedditExtractoR package to store the top 500 comments from each thread into a dataset. However, due to the unreliable nature of that package’s functions, I do not reproduce that code in this document. Instead, I import the datasets from my personal github page.
comments <- read_csv("https://raw.githubusercontent.com/Reed-Statistics/f1_reddit_comments/master/all_comments.csv?token=ANDSWNKBJYU2JJNFAQCFFNS6XB3SI")
comments_two <- read_csv("https://raw.githubusercontent.com/Reed-Statistics/f1_reddit_comments/master/all_comments_two.csv?token=ANDSWNIPHZAWRIUZKYCLB5S6XCDFS")
comments <- rbind(comments, comments_two)
comments <- comments %>%
select(1, 3, 4, 12, 14, 20)Next, I created a dataset of the sentences in each comment, making sure to removing some buggy symbols that prevented the sentiment analysis from running. I then ran the sentiment_by function from sentimentR to get the sentiment of each sentence.
non_utf <- comments %>% filter(utf8_valid(comments$comment) == FALSE)
comments <- comments %>%
filter(utf8_valid(comments$comment) == TRUE) %>%
mutate(comment = str_replace_all(comment, "\\\\u0019", "")) %>%
mutate(comment = str_replace_all(comment, "\\\\n", "")) %>%
mutate(comment = str_replace_all(comment, "\\\\u002", "")) %>%
mutate(comment = str_replace_all(comment, "\\\\", ""))
comment_sentences <- comments %>%
unnest_tokens(output = sentence, input = comment, token = "sentences") %>%
mutate(index = 1:17414)
comment_sentiment <- sentiment_by(comment_sentences$sentence)
comment_sentences <- comment_sentences %>%
left_join(comment_sentiment, by = c("index" = "element_id"))I then average the sentiments of the comments from each post-race thread. The score for each race is numeric, with a minimum of -0.01158374 and a maximum of 0.07097164.
sentiment_by_race <- comment_sentences %>%
group_by(race) %>%
summarise(mean(ave_sentiment)) %>%
rename(sentence_score = 2) %>%
arrange(desc(sentence_score))
head(sentiment_by_race)## # A tibble: 6 x 2
## race sentence_score
## <chr> <dbl>
## 1 Austrian GP 0.0710
## 2 Australian GP 0.0581
## 3 Italian GP 0.0559
## 4 Singapore GP 0.0553
## 5 German GP 0.0471
## 6 Hungarian GP 0.0441I also tried examining the sentiments of each thread by words instead of sentences. The scatterplot below shows that the two scored are highly correlated, meaning that races scored similarly whether I used sentences or words. However, because running the analysis with sentences allows for more nuance, I choose to continue using the sentiment scores for the analysis I did with sentences.
afinn <- get_sentiments("afinn")
races_afinn <- comment_sentences %>%
unnest_tokens(output = word, input = sentence, token = "words") %>%
inner_join(afinn, by = "word") %>%
group_by(race) %>%
summarise(mean(value)) %>%
rename(word_score = 2)
sentiment_by_race <- sentiment_by_race %>%
left_join(races_afinn, by = c("race" = "race")) %>%
mutate(race = fct_reorder(race, sentence_score))
ggplot(sentiment_by_race, aes(x = sentence_score, y = word_score)) +
geom_point() +
geom_smooth(method = "lm") +
theme_bw() +
labs(x = "Sentiment score by sentence", y = "Sentiment score by word",
title = "Scatterplot of sentiment analysis scores using different tokens")
Who Wins? Does It Matter?
One common refrain among Formula 1 fans is that the sport is boring because the Mercedes AMG Formula 1 team is so dominant. I hypothesized that races where a team other than Mercedes wins may be more popular with fans. In order to test this, I used the ErgastR API wrapper to get data about the winners of each race in the 2019 season. I added this information to the dataset containing the sentence-level sentiments.
race_list <- list()
results_finder <- for(i in 1:21){
result <- raceWinner(2019, i)
result <- result %>%
as.data.frame() %>%
mutate("number" = i)
race_list[[i]] <- result
}
race_results <- do.call("rbind", race_list)
race_numbers <- racesData.df(2019) %>%
mutate(round = as.integer(round))
driver_teams <- seasonStandings(2019) %>%
select(2, 7)
race_results <- race_results %>%
left_join(race_numbers, by = c("number" = "round")) %>%
select(1:3) %>%
mutate(racename = as.character(racename)) %>%
mutate(race = str_replace(racename, "Grand Prix", "GP")) %>%
rename(driver_winner = 1) %>%
select(1, 2, 4) %>%
left_join(driver_teams, by = c("driver_winner" = "driverId")) %>%
rename(team_winner = 4)
sentiment_by_race <- sentiment_by_race %>%
left_join(race_results, by = "race") %>%
mutate(race = fct_reorder(race, sentence_score))I then arranged the races from the most positive comments to the most negative, and made each bar the color of the winning team. This plot seems to confirm my suspicions. Non-Mercedes teams only won 6 of the season’s 21 races, but 4 of the top 5 races according to sentiments were won by non-Mercedes teams. Meanwhile, the 5 lowest rated races were all Mercedes wins. Formula 1 fans like variety; a non-Mercedes win generated more positive comments from the community.
ggplot(sentiment_by_race, aes(x = race, y = sentence_score, fill = team_winner)) +
geom_bar(stat = "identity") +
scale_fill_manual(values = c("#00D2BE", "#1E41FF", "#ff2800")) +
coord_flip() +
theme_bw() +
labs(x = "Race", y = "Sentiment Score by Sentence", fill = "Winning Team",
title = "Reddit Comment Sentiments by Race and Winning Team") 
Looking Geographically
Next I wanted to visualize the sentiments spacially. Most Formula 1 fans are European, are they biased towards races in Europe, which tend to use historic tracks? I also used this as an opportunity to visualize the global nature of the sport. First I recorded the coordinates of each circuit on the 2019 calendar.
city_list <- list()
city_list[[1]] <- c("Australian GP", -37.850351, 144.969600)
city_list[[2]] <- c("Bahrain GP", 26.032111, 50.512449)
city_list[[3]] <- c("Chinese GP", 31.339471, 121.221735)
city_list[[4]] <- c("Azerbaijan GP", 40.372256, 49.851681)
city_list[[5]] <- c("Canadian GP", 45.503068, -73.526945)
city_list[[6]] <- c("Monaco GP", 43.736372, 7.421179)
city_list[[7]] <- c("French GP", 43.251623, 5.792785)
city_list[[8]] <- c("Hungarian GP", 47.582107, 19.251120)
city_list[[9]] <- c("Austrian GP", 47.219619, 14.765161)
city_list[[10]] <- c("Spanish GP", 41.568374, 2.256849)
city_list[[11]] <- c("Belgian GP", 50.436843, 5.971685)
city_list[[12]] <- c("Italian GP", 45.621664, 9.284854)
city_list[[13]] <- c("Singapore GP", 1.291260, 103.863781)
city_list[[14]] <- c("Russian GP", 43.409806, 39.968844)
city_list[[15]] <- c("United States GP", 30.134505, -97.636096)
city_list[[16]] <- c("Mexican GP", 19.402752, -99.089314)
city_list[[17]] <- c("Abu Dhabi GP", 24.470010, 54.605120)
city_list[[18]] <- c("Japanese GP", 34.845549, 136.538963)
city_list[[19]] <- c("Brazilian GP", -23.701293, -46.698094)
city_list[[20]] <- c("British GP", 52.073268, -1.014427)
city_list[[21]] <- c("German GP", 49.329791, 8.571032)
city_coords <- do.call("rbind", city_list) %>%
as.data.frame() %>%
rename(city = 1,
latitude = 2,
longitude = 3) %>%
mutate(latitude = as.numeric(levels(latitude))[latitude],
longitude = as.numeric(levels(longitude))[longitude]) %>%
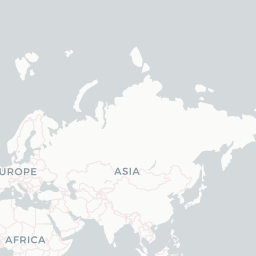
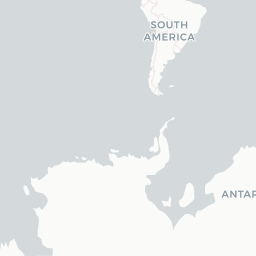
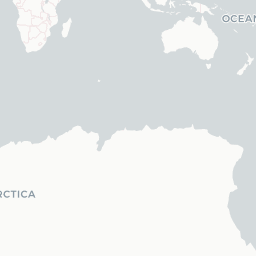
left_join(sentiment_by_race, by = c("city" = "race"))Using leaflet pop-ups, I was able to include a greater amount of information about each race without overwhelming the viewer. The results seem pretty mixed. I do find that the sentiments regarding races in the Americas seem to be lower than in other regions.
race_info <- paste("<b>", "Race:", "</b>", city_coords$city, "</br>",
"<b>", "Winner:", "</b>", str_to_title(city_coords$driver_winner), "—",
str_to_title(city_coords$team_winner), "</br>",
"<b>", "Sentiment Score:","</b>", city_coords$sentence_score)
pal <- colorNumeric(palette = c("red", "green"),
domain = city_coords$sentence_score)
leaflet(options = leafletOptions(minZoom = 1, maxZoom = 6)) %>%
addProviderTiles(providers$CartoDB.Positron) %>%
addCircleMarkers(lng = ~longitude, lat = ~latitude,
data = city_coords, color = ~pal(city_coords$sentence_score),
stroke = FALSE, fillOpacity = 0.9, popup = race_info)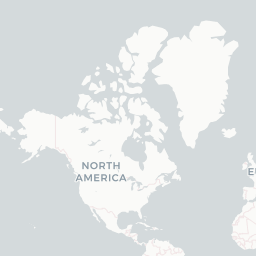
Does Sentiment Analysis Correspond With Other Fan Rankings?
Throughout this project I was concerned about the ability of sentiment analysis of Reddit comments to really capture how people felt about a race. First of all, sentiment analysis cannot account for irony or sarcasm, which are very common on Reddit. More importantly, the most beloved Formula 1 races are often the most controversial. For F1 fans, the worst thing a race can be is boring.
Close wheel-to-wheel racing, manoeuvres that test the limits of the rules, and shocking moments all contribute to an exciting race, but may also illicit strong emotions that will end up being coded negative in a sentiment analysis. To test whether sentiment analysis was truly a good measure of how people felt about a race, I took data from Racefans.net, which compiled the average score its readership gave each race on a scale of 1 to 10.
race_fans <- data.frame("race" = c("Australian GP", "Bahrain GP",
"Chinese GP", "Azerbaijan GP",
"Spanish GP", "Monaco GP",
"Canadian GP", "French GP",
"Austrian GP", "British GP",
"German GP", "Hungarian GP",
"Belgian GP", "Italian GP",
"Singapore GP", "Russian GP",
"Japanese GP", "Mexican GP",
"United States GP", "Brazilian GP",
"Abu Dhabi GP"),
"race_fans" = c(6.3, 8.5, 4.8, 5.4,
4.6, 6.3, 4.4, 3.5, 8.9,
8.6, 9.4, 4.6, 7.5, 8.2, 6.2, 5.8, 6.9, 6.6, 7,
8.8, 5.6))
sentiment_by_race <- left_join(sentiment_by_race, race_fans, by = c("race" = "race"))
ggplot(sentiment_by_race, aes(x = race_fans, y = sentence_score, label = race)) +
geom_point(color = "violetred3") +
stat_smooth(method = "lm", alpha = 0.2, color = "violet") +
geom_text_repel(size = 3) +
labs(x = "Fan Score on Racefans.net", y = "Sentiment of Comments",
title = "Highly Rated Races Don't Always Produce Positive Comments") +
theme_bw() The scatterplot shows that there is a slightly positive correlation between the ratings the fans gave the races and the sentiments expressed in Reddit comments. In other words: highly rated races had more positive comments. That being said, the margin of error on the regression line shows that there could easily be no correlation between the two at all.
The scatterplot shows that there is a slightly positive correlation between the ratings the fans gave the races and the sentiments expressed in Reddit comments. In other words: highly rated races had more positive comments. That being said, the margin of error on the regression line shows that there could easily be no correlation between the two at all.
One key example of how comment sentiment doesn’t necessarily lead to a 1-10 rating is the Brazilian GP. The race was very exciting, but several incidents that ended with several fan-favorite drivers not finishing the race may have provoked negative comments. Nonetheless, the exciting final laps and surprise podium by a midfield team led many to rate the race the second best of the season. This plot just shows that sentiment analysis is not a foolproof tool for divining actual feelings. More broadly, it reflects that the way we value sports is not always in how positive they make us feel. Often the events that are the most polarizing or emotionally intense are the ones we remember as classics.
That being said, there is some correspondence between the two scores. The French Grand Prix committed the cardinal sin of being boring. The Canadian Grand Prix ended with a highly controversial decision by the stewards (F1’s referees) that resulted in Ferrari driver Sebastian Vettel coming in second despite crossing the line first. Meanwhile, Mercedes driver Lewis Hamilton was awarded the win. The technicality was seen by many to undermine “real racing”, and, combined with another Mercedes win in an already dominant season, led to the race being panned both on Reddit and on RaceFans.
Conclusion
Reddit comments can provide insights directly into the feelings of online communities. By analyzing the comments on r/formula1, I showed how doing sentiment analysis on specific Reddit threads can represent the opinions of sports fans on various events. This approach is especially apt for Formula 1, where all teams compete in the same event together, as opposed to most sports where two teams compete against each other in a league. All Formula 1 fans reacting together in one Reddit thread proved to be a good, though not imperfect, proxy for fan attitudes towards the races in the 2019 Formula 1 season.